
- Running Empirical Investigation Locally is Not Quite Viable
- How We Conduct DRL Empirical Investigation via AWS Batch
- Step 0.1: Manage Experiments with Weights and Biases
- Step 0.2: Code Deployment via Docker
- Step 1: Setup AWS Batch
- Step 2. Run Experiments (Simple Scenario: Benchmark Apex DQN)
- Step 2.1. Directly Run Scripts via
nohup - Step 2.2. Run via the CleanRL Docker Image
- Step 2.3. Run via the AWS Batch
- Step 2.3. Generate Publish Quality Tables and Figures
- 💸 Affordable Cost
- 🎁 Bonus. Run the Open RL Benchmark
- Step 3. Empirical Investigation (Research Example)
- Step 3.1. Experiment Setup
- Step 3.2. Submitting Jobs
- 🎯 Step 3.3. Quick Insight Discovery with Weights and Biases
- 📝 Step 3.4. Generate Publish Quality Tables and Figures
- 💸 Affordable Cost
Running Empirical Investigation Locally is Not Quite Viable
Recently, empirical investigation has been of increasing importance in the workflow of Deep Reinforcement Learning (DRL) research. Say you developed a wonderful DRL algorithm that works with some proof-of-concept domains and it's time to examine its effectiveness more comprehensively. It is considered the best practices to do but not limited to the following:
- Conduct experiments with more random seeds.
- You therefore choose 10 random seeds (although https://arxiv.org/abs/1806.08295 recommends a whopping 20 random seeds)
- Perform ablation study.
- You therefore perform ablation study on your algorithm that consists of 3 components.
- Examine the impact of important hyper-parameters.
- You therefore examine 4 hyper-parameters for each component.
- Compare against existing methods as baselines.
- You therefore choose 2 existing algorithms as baselines
- Evaluate the agents in a variety of tasks.
- You therefore examine its performance in 5 different tasks
It does not take much time for you to realize you have to do ((1+3)*4 + 2)*10*5=900, which basically blows up combinatorially. If you somehow find a bug, redoing the experiments brings the number to 900*2 = 1,800 (trust me this happens). This number is probably not even friendly to some university's lab workstation. It would be quite desirable to have more flexible computational power in the cloud such as AWS, GCP or Azure.
In this blog post, I will try to describe a workflow with CleanRL (https://github.com/vwxyzjn/cleanrl) and AWS Batch that has worked like a poor man's Google Scale for me and empowers me to discover insights for research like never before.
This workflow is relatively much more accessible to researchers with small computational power since all of the tools and infrastructures are publicly available. It can definitely be expensive, but in my experience the productivity it brings is worth it.
Note that most experiments (200+) with our Open RL Benchmark (http://benchmark.cleanrl.dev/) were conducted using this workflow.
How We Conduct DRL Empirical Investigation via AWS Batch
Step 0.1: Manage Experiments with Weights and Biases
Central to our workflow is proper experiment management to help us record important information and discover insights. We log all of our experiments using Weights and Biases so that you can check the following information:
- hyper-parameters (check it at the Overview tab of a run)
- training metrics (e.g. episode reward, training losses. Check it at the Charts tab of a run)
- videos of the agents playing the game (check it at the Charts tab of a run)
- system metrics (e.g. CPU utilization, memory utilization. Check it at the Systems tab of a run)
stdout, stderrof the script (check it at the Logs tab of a run)- all dependencies (check
requirements.txtat the Files tab of a run)) - source code (this is especially helpful since we have single file implementation, so we know exactly all of the code that is responsible for the run. Check it at the Code tab of a run))
- the exact commands to reproduce it (check it at the Overview tab of a run. Public access is blocked by https://github.com/wandb/client/issues/1177).
This experiment management is truly amazing; we know exactly which files are responsible for the results, and its tooling allows us to sort, group, and filter experiments. It is *significantly* easier to dig insights and manage versions. Check out example reports such as https://app.wandb.ai/cleanrl/cleanrl.benchmark/reports/Apex-DQN-vs-DQN--VmlldzoyMTAzMTI, which helps us to understand the how much faster can Apex DQN learn compared to DQN.
Step 0.2: Code Deployment via Docker
Previously, I had some web development experience and that taught me about docker, which is a great tool for making the build process reproducible when deploying code to the cloud. This is going to be the basis of our approach.
We have a simple Dockerfile that can be found at https://github.com/vwxyzjn/cleanrl/blob/master/docker/Dockerfile. It will create a CleanRL docker container that will have games such as Atari, Pybullet, etc, and common dependencies pre-installed.
FROM pytorch/pytorch:1.4-cuda10.1-cudnn7-runtime
RUN apt-get update && \
apt-get -y install xvfb ffmpeg git build-essential
RUN pip install gym[box2d,atari] pybullet==2.8.1
RUN git clone https://github.com/vwxyzjn/cleanrl && \
cd cleanrl && pip install -e .
RUN apt-get -y install python-opengl
RUN pip install opencv-python
RUN pip install seaborn pandas
RUN pip install stable-baselines3
WORKDIR /workspace/cleanrl/cleanrl
COPY entrypoint.sh /usr/local/bin/
RUN chmod 777 /usr/local/bin/entrypoint.sh
ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
CMD python ppo2_continuous_action.py --capture-video --total-timesteps 200If you are not doing research with other game environments, you can probably just use our pre-built docker container vwxyzjn/cleanrl:latest (https://hub.docker.com/r/vwxyzjn/cleanrl) with existing algorithms as follows (I will talk more on how to run new algorithms with the CleanRL container later).
docker run -d --cpuset-cpus="0" \
-e WANDB={REPLACE_WITH_YOUR_WANDB_KEY} \
vwxyzjn/cleanrl:latest python ppo_atari_visual.py \
--gym-id BeamRiderNoFrameskip-v4
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark
--prod-mode --capture-video --seed 1Otherwise feel free to adding new dependencies in the Dockerfile and build and push the docker image with
# you are at the cleanrl root directly
cd docker
# change the username of `vwxyzjn` in `build.sh`
bash build.shStep 1: Setup AWS Batch
AWS Batch is a managed batch processing service and it is our preferred way to run thousands of experiments at scale. Below is a screenshot of "why use aws batch".

The essential idea is to submit jobs with the CleanRL docker containers and let AWS Batch queue them.
To start using it, follow thses steps as demonstrated in the video below:
- Get the access key and secret from aws console as shown in the screenshots below. Click on your name in the top right -> My Security Credentials -> Create New Access Key

- Then install the
aws-cliand use it as the follows:pip install awscli aws configure
- Go to AWS Batch and setup three compute environments
cleanrl, cleanrl_gpu, cleanrl_gpu_large_memory, which all use the cheap preemptible spot instances. Then use https://github.com/vwxyzjn/cleanrl/blob/master/benchmark/setup.py to create the corresponding job queues, and the CleanRL job definition as shown in the videos below.
where the compute environment are configured differently intended for various algorithms. See the table below for the descriptions.
CleanRL Compute Environment Presets
| Compute environment | Description |
|---|---|
| cleanrl | uses instance c5d.large (2 vCPU 4 GiB RAM) for regular cpu intensive experiments such as PPO. |
| cleanrl_gpu | uses instance g4dn.xlarge (4 vCPU 16 GiB RAM, 1 GPU) for gpu intensive experiments such as TD3, DDPG, SAC, and others. |
| cleanrl_gpu_large_memory | uses instance g4dn.4xlarge (16 vCPU 64 GiB RAM, 1 GPU) for gpu and memory intensive experiments such as DQN, and C51 with Atari games, which generally require replay size of 1M. |
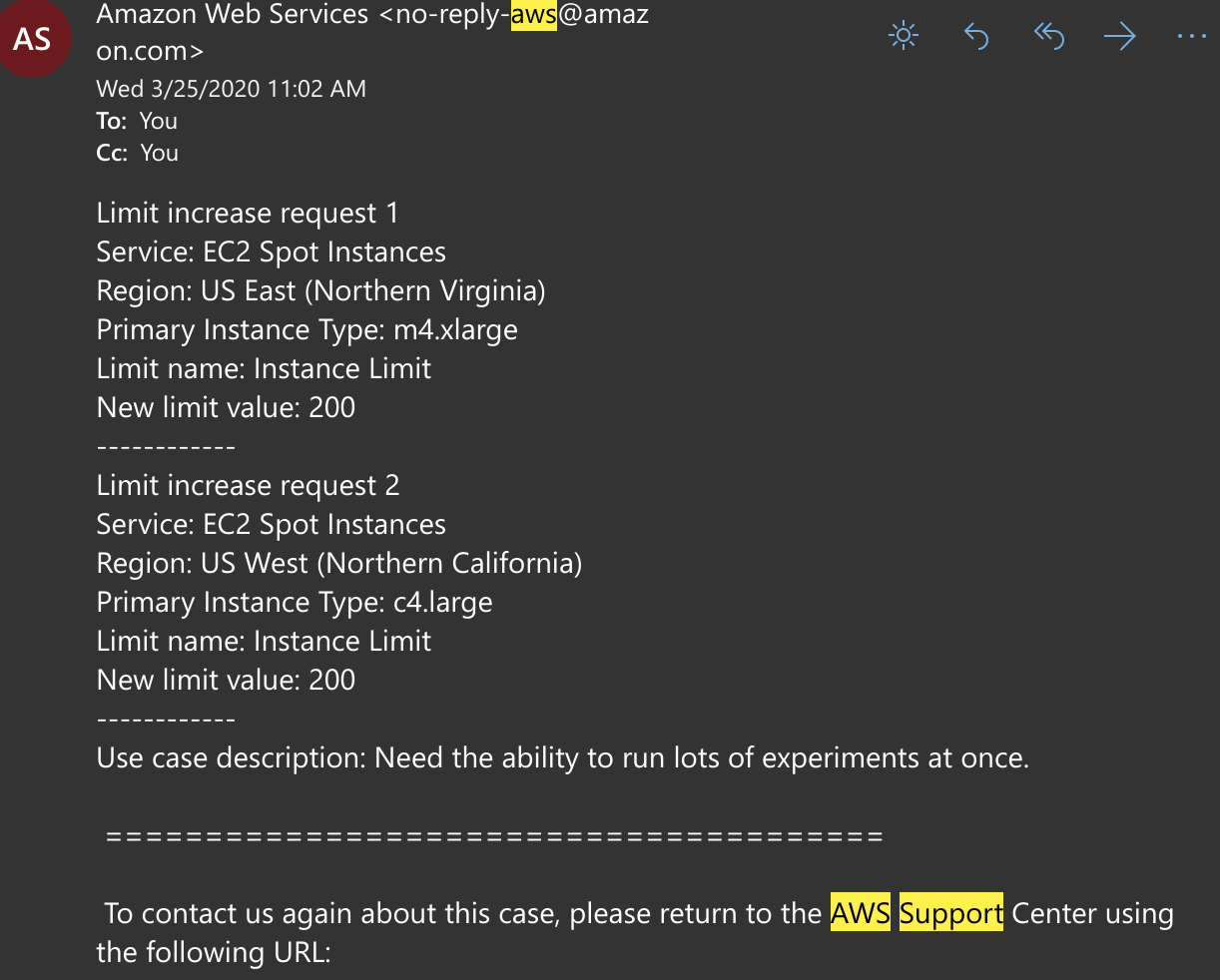
If you are using AWS Batch for the first time, it is also likely that you need to request higher limit for spot instances. See more at https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-limits.html#spot-limits-general. You will get an email like the following and it takes up to couple days for the request to be approved.
Step 2. Run Experiments (Simple Scenario: Benchmark Apex DQN)
It's time to setup the experiments! We will start with a simple scenario of examining Apex DQN (an existing implementation at https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/apex_dqn_atari_visual.py) in five Atari games. So we generate the experiments to using https://github.com/vwxyzjn/cleanrl/blob/master/benchmark/generate_exp.py by executing:
# you should delete `--wandb-entity`
python generate_exp.py --exp-script scripts/apex_dqn_atari.sh \
--algo apex_dqn_atari_visual.py \
--total-timesteps 10000000 \
--gym-ids BeamRiderNoFrameskip-v4 QbertNoFrameskip-v4 SpaceInvadersNoFrameskip-v4 PongNoFrameskip-v4 BreakoutNoFrameskip-v4 \
--wandb-project-name cleanrl.benchmark \
--other-args "--wandb-entity cleanrl --cuda True"which generates a scripts/apex_dqn_atari.sh. From here on, there are three ways to run experiments.
Step 2.1. Directly Run Scripts via nohup
This is the simplest way to run experiments with CleanRL and it is also what we have used since the early stages of the project. The commands in scripts/apex_dqn_atari.sh may be run directly on a local server:
# scripts/apex_dqn_atari.sh
for seed in {1..2}
do
(sleep 0.3 && nohup xvfb-run -a python apex_dqn_atari_visual.py \
--gym-id BeamRiderNoFrameskip-v4 \
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark \
--prod-mode \
--wandb-entity cleanrl --cuda True \
--capture-video \
--seed $seed
) >& /dev/null &
done
for seed in {1..2}
do
(sleep 0.3 && nohup xvfb-run -a python apex_dqn_atari_visual.py \
--gym-id QbertNoFrameskip-v4 \
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark \
--prod-mode \
--wandb-entity cleanrl --cuda True \
--capture-video \
--seed $seed
) >& /dev/null &
done
for seed in {1..2}
do
(sleep 0.3 && nohup xvfb-run -a python apex_dqn_atari_visual.py \
--gym-id SpaceInvadersNoFrameskip-v4 \
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark \
--prod-mode \
--wandb-entity cleanrl --cuda True \
--capture-video \
--seed $seed
) >& /dev/null &
done
for seed in {1..2}
do
(sleep 0.3 && nohup xvfb-run -a python apex_dqn_atari_visual.py \
--gym-id PongNoFrameskip-v4 \
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark \
--prod-mode \
--wandb-entity cleanrl --cuda True \
--capture-video \
--seed $seed
) >& /dev/null &
done
for seed in {1..2}
do
(sleep 0.3 && nohup xvfb-run -a python apex_dqn_atari_visual.py \
--gym-id BreakoutNoFrameskip-v4 \
--total-timesteps 10000000 \
--wandb-project-name cleanrl.benchmark \
--prod-mode \
--wandb-entity cleanrl --cuda True \
--capture-video \
--seed $seed
) >& /dev/null &
doneStep 2.2. Run via the CleanRL Docker Image
Alternatively, you could also run the experiments using the CleanRL docker image, we can run https://github.com/vwxyzjn/cleanrl/blob/master/benchmark/jobs.py by executing:
SUBMIT_AWS=False
WANDB_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
python jobs.py --exp-script scripts/apex_dqn_atari.sh \
--job-queue cleanrl_gpu_large_memory \
--job-definition cleanrl \
--num-seed 2 \
--num-vcpu 16 \
--num-gpu 1 \
--num-memory 63000 \
--num-hours 48.0 \
--wandb-key $WANDB_KEY \
--submit-aws $SUBMIT_AWSIt will give you the following outputs that can be executed directly
docker run -d --cpuset-cpus="0" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id BeamRiderNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 1"
docker run -d --cpuset-cpus="1" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id BeamRiderNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 2"
docker run -d --cpuset-cpus="2" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id QbertNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 1"
docker run -d --cpuset-cpus="3" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id QbertNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 2"
docker run -d --cpuset-cpus="4" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id SpaceInvadersNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 1"
docker run -d --cpuset-cpus="5" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id SpaceInvadersNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 2"
docker run -d --cpuset-cpus="6" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id PongNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 1"
docker run -d --cpuset-cpus="7" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id PongNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 2"
docker run -d --cpuset-cpus="8" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id BreakoutNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 1"
docker run -d --cpuset-cpus="9" -e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx vwxyzjn/gym-microrts:latest /bin/bash -c "python apex_dqn_atari_visual.py --gym-id BreakoutNoFrameskip-v4 --total-timesteps 10000000 --wandb-project-name cleanrl.benchmark --prod-mode --wandb-entity cleanrl --cuda True --capture-video --seed 2"Step 2.3. Run via the AWS Batch
So if you'd like, you can choose to run the experiments locally via the two previous methods, and sometimes I find running docker with restricted CPU set to be very helpful. However, each Apex DQN experiment takes about 20-30 GBs of RAM (while regular DQN requires 30-60 GBs of RAM for 1M experience replay), at least 6 CPU cores, and 1 GPU. In total, it requires 200-300 GBs of RAM, 60 CPUs, and 10 GPUs. This amount of compute is likely out of reach for personal computers, small lab workstations, or even the clusters of the university or company. I suspect this is the reason that for most small to medium sized RL libraries do not do Atari benchmarks or only do benchmark PongNoFrameSkip-v4. With that in mind, let's submit it to AWS
SUBMIT_AWS=True
python jobs.py --exp-script scripts/apex_dqn_atari.sh \
--job-queue cleanrl_gpu_large_memory \
--job-definition cleanrl \
--num-seed 2 \
--num-vcpu 16 \
--num-gpu 1 \
--num-memory 63000 \
--num-hours 48.0 \
--submit-aws $SUBMIT_AWSThe the following video demonstrates what happens
Step 2.3. Generate Publish Quality Tables and Figures
We hope that our workflow eventually could eventually results in publishable research. To do so, generating publish quality tables and figures would be important. We provide one such utility script precisely does so:
I actually ran it with the cleanrl/cleanrl.benchmark so it takes about 5-10 minutes to generate these.
.svg?width=720&table=block&id=c47aa8c0-1213-4750-b81e-d0f7cf61ca7a)






💸 Affordable Cost
These experiments (just the apex_dqn_atari_visual.py) cost in total 11.87+5.12=16.99 dollars for the computation resources of 10 g4dn.4xlarge spot instance (16 vCPU 64 GiB RAM, 1 GPU) for about 3-4 hours, after which these instances are automatically terminated.

It is definitely not cheap, but it is affordable. Note that if I were to use my own machine (24 vCPU, 64 GiB RAM, 1 GPU) to run these experiments, it would have taken 30-40 hours assuming I somehow manage to execute experiments perfectly sequencial. In a sense, this is a 10x improvement in productivity if these experiment results are important to me.
🎁 Bonus. Run the Open RL Benchmark
We are now ready to give the instructions on how to reproduce the Open RL Benchmark in its entirety. Simply go to cleanrl/benchmark folder and run
# manually replace all instances of `--wandb-entity cleanrl` with
# the empty string or your own wandb entity
bash generate_exp.sh
# manually change the `SUBMIT_AWS=False` to `SUBMIT_AWS=True`
# in benchmark_submit.sh, then run
bash jobs.sh
# however, all of the mujoco experimetns such as
# `cleanrl/benchmark/scripts/td3_mujoco.sh` have to be run by hand
# unless you have a mujoco institutional license.Step 3. Empirical Investigation (Research Example)
In this section, I will actually use my own research a real example. In our latest work, my advisor Santiago Ontañón (twitter @santiontanon) and I introduce a new technique called action guidance (https://arxiv.org/abs/2010.03956). For more details of the technique, please refer to the paper. However, for the purpose of this blog post, we will only focus on its experiment design.
Step 3.1. Experiment Setup
Here is the list of best practices for empirical investigation and how we address them:
- Conduct experiments with more random seeds.
- We use 10 random seeds
- Perform ablation study.
- We perform ablation study on 1 component (with the name PLO)
- Examine the impact of important hyper-parameters.
- We examine 3 possible hyper-parameters (with the names short adaptation, long adaptation, mixed policy)
- Compare against existing methods as baselines.
- We compare 2 existing approaches (with the names sparse reward and shaped reward)
- Evaluate the agents in a variety of tasks.
- We evaluate in 3 tasks (LearnToAttack, ProduceCombatUnit, DefeatRandomEnemy)
In total, we have 270 experiments to be conducted. So we generate the experiments to using https://github.com/vwxyzjn/cleanrl/blob/master/benchmark/generate_exp.py by writing the following bash script
WANDB_ENTITY=anonymous-rl-code
# main results
python generate_exp.py --exp-script scripts/ppo_sparse.sh \
--algo ppo.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name sparse-reward --cuda True"
python generate_exp.py --exp-script scripts/ppo_shaped.sh \
--algo ppo.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackShapedReward-v1 MicrortsProduceCombatUnitsShapedReward-v1 MicrortsRandomEnemyShapedReward3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name shaped-reward-plo --cuda True"
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name short-adaptation-plo --cuda True --shift 800000"
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward1.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name long-adaptation-plo --cuda True --shift 2000000 --adaptation 7000000"
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward2.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name mixed-policy-plo --cuda True --shift 2000000 --adaptation 2000000 --end-e 0.5"
# ablation study
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward3.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name short-adaptation --cuda True --shift 800000 --positive-likelihood 1.0"
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward4.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name long-adaptation --cuda True --shift 2000000 --adaptation 7000000 --positive-likelihood 1.0"
python generate_exp.py --exp-script scripts/ppo_ac_positive_reward5.sh \
--algo ppo_ac_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name mixed-policy --cuda True --shift 2000000 --adaptation 2000000 --end-e 0.5 --positive-likelihood 1.0"
python generate_exp.py --exp-script scripts/ppo_positive_reward.sh \
--algo ppo_positive_reward.py \
--total-timesteps 10000000 \
--gym-ids MicrortsAttackHRL-v1 MicrortsProduceCombatUnitHRL-v1 MicrortsRandomEnemyHRL3-v1 \
--wandb-project-name action-guidance \
--other-args "--exp-name sparse-reward-plo --cuda True"We would like to continue using the docker image to run the experiments. In this case, we used a different docker image vwxyzjn/gym-microrts based on this Dockerfile, which additionally installs MicroRTS for our research. We also setup a job definition on AWS based on this file.
Step 3.2. Submitting Jobs
Before submitting our experiments to the cloud, we want the docker containers to be able to pull the our latest files that are internal or confidential. Technically we could use some storage options that require some sort of authentication schema, but currently we just simply use Netlify to create a temporary storage.
# install the netlify CLI here https://docs.netlify.com/cli/get-started/
(base) [costa1@costa-pc action-guidence]$ netlify deploy --prod --dir dist
Deploy path: /home/costa/Documents/work/go/src/github.com/vwxyzjn/action-guidence/dist
Deploying to main site URL...
✔ Finished hashing 4 files
✔ CDN requesting 0 files
✔ Finished uploading 0 assets
✔ Deploy is live!
Logs: https://app.netlify.com/sites/rlcodestorage/deploys/xxxxxxxxxxxxxxxx
Unique Deploy URL: https://5f4484a143b94138ee17xxxxxxxxxx.netlify.app
Website URL: https://example.netlify.appAnd we submit the related experiments using https://github.com/vwxyzjn/cleanrl/blob/master/benchmark/jobs.py by writing the following bash script
SUBMIT_AWS=False
UPLOAD_FILES_BASEURL=https://xxxx.example.com
WANDB_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx # production
python jobs.py --exp-script scripts/ppo_ac_positive_reward.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_ac_positive_reward1.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_ac_positive_reward2.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_ac_positive_reward3.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_ac_positive_reward4.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_positive_reward.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_shaped.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
python jobs.py --exp-script scripts/ppo_sparse.sh \
--job-queue cleanrl \
--wandb-key $WANDB_KEY \
--job-definition gym-microrts \
--num-seed 10 \
--num-vcpu 2 \
--num-memory 7000 \
--num-hours 24.0 \
--upload-files-baseurl $UPLOAD_FILES_BASEURL \
--submit-aws $SUBMIT_AWS
which basically generates the following docker containers. The basic idea is to download from my internal script ppo_ac.py from a temporary site via wget https://5f4484a143b94138ee17xxxxxxxxxx.netlify.app/ppo_ac.py, then execute the related python commands.
docker run -d --cpuset-cpus="0" \
-e WANDB=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
vwxyzjn/gym-microrts:latest /bin/bash -c \
"wget https://5f4484a143b94138ee17xxxxxxxxxx.netlify.app/ppo_ac.py ; python ppo.py --gym-id MicrortsRandomEnemyHRL3-v1 --total-timesteps 10000000 --wandb-project-name action-guidance --prod-mode --exp-name sparse-reward --cuda True --capture-video --seed 10"🎯 Step 3.3. Quick Insight Discovery with Weights and Biases
After the experiments are logged, we can create reports that help with insights discovery. As an example, check out our report for the paper:
📝 Step 3.4. Generate Publish Quality Tables and Figures
We hope that our workflow eventually could eventually results in publishable research. To do so, generating publish quality tables and figures would be important. We provide one such utility script precisely does so:
For this particular research project, we used a slightly older version of plots.py that you can find here. After running the script, it prints out the following message:
data loaded
{'ppo': (0.2980392156862745, 0.4470588235294118, 0.6901960784313725), 'ppo_ac_positive_reward-shift-2000000--adaptation-2000000--positive_likelihood-0-': (0.8666666666666667, 0.5176470588235295, 0.3215686274509804), 'ppo_ac_positive_reward-shift-2000000--adaptation-7000000--positive_likelihood-0-': (0.3333333333333333, 0.6588235294117647, 0.40784313725490196), 'ppo_ac_positive_reward-shift-2000000--adaptation-7000000--positive_likelihood-1-': (0.7686274509803922, 0.3058823529411765, 0.3215686274509804), 'ppo_ac_positive_reward-shift-800000--adaptation-1000000--positive_likelihood-0-': (0.5058823529411764, 0.4470588235294118, 0.7019607843137254), 'ppo_ac_positive_reward-shift-800000--adaptation-1000000--positive_likelihood-1-': (0.5764705882352941, 0.47058823529411764, 0.3764705882352941), 'ppo_positive_reward-positive_likelihood-0-': (0.8549019607843137, 0.5450980392156862, 0.7647058823529411), 'pposhaped': (0.5490196078431373, 0.5490196078431373, 0.5490196078431373)}
MicrortsProduceCombatUnitHRL-v1's data loaded
MicrortsRandomEnemyHRL3-v1's data loaded
MicrortsAttackHRL-v1's data loaded
\begin{tabular}{llll}
\toprule
gym\_id & MicrortsAttackHRL-v1 & MicrortsProduceCombatUnitHRL-v1 & MicrortsRandomEnemyHRL3-v1 \\
exp\_name & & & \\
\midrule
action guidance - long adaptation & 0.00 $\pm$ 0.00 & 8.31 $\pm$ 2.62 & 0.00 $\pm$ 0.01 \\
action guidance - long adaptation w/ PLO & 0.00 $\pm$ 0.00 & 6.96 $\pm$ 4.04 & 0.00 $\pm$ 0.00 \\
action guidance - multi-agent w/ PLO & 0.00 $\pm$ 0.00 & 9.36 $\pm$ 0.35 & 0.00 $\pm$ 0.00 \\
action guidance - short adaptation & 0.00 $\pm$ 0.00 & 2.95 $\pm$ 4.48 & 0.00 $\pm$ 0.00 \\
action guidance - short adaptation w/ PLO & 0.00 $\pm$ 0.00 & 9.48 $\pm$ 0.51 & 0.00 $\pm$ 0.01 \\
shaped reward & 0.00 $\pm$ 0.00 & 9.57 $\pm$ 0.30 & 1.77 $\pm$ 1.83 \\
sparse reward & 0.00 $\pm$ 0.00 & 0.00 $\pm$ 0.01 & 0.00 $\pm$ 0.00 \\
sparse reward - no PLO & 0.00 $\pm$ 0.00 & 0.00 $\pm$ 0.01 & 0.00 $\pm$ 0.00 \\
\bottomrule
\end{tabular}and you can render the table and find the image at action-guidence/plots/charts_episode_reward_ProduceCombatUnitRewardFunction/plots/MicrortsProduceCombatUnitHRL-v1.pdf
.svg?width=860&table=block&id=8578d490-4623-46c8-9e56-d32adcfbe441)


💸 Affordable Cost
As for the costs of the action guidance experiments, it is a little tricky to estimate because 1) the costs are posted in a delayed fashion and 2) I have other projects running at the same time. However, I can make an accurate estimate. The 30 action guidance experiments on 9/19/20 costs $26, so in total for 270 experiments in the project it should cost $234. And all experiments should finish overnight since each of them only takes 4 hours.
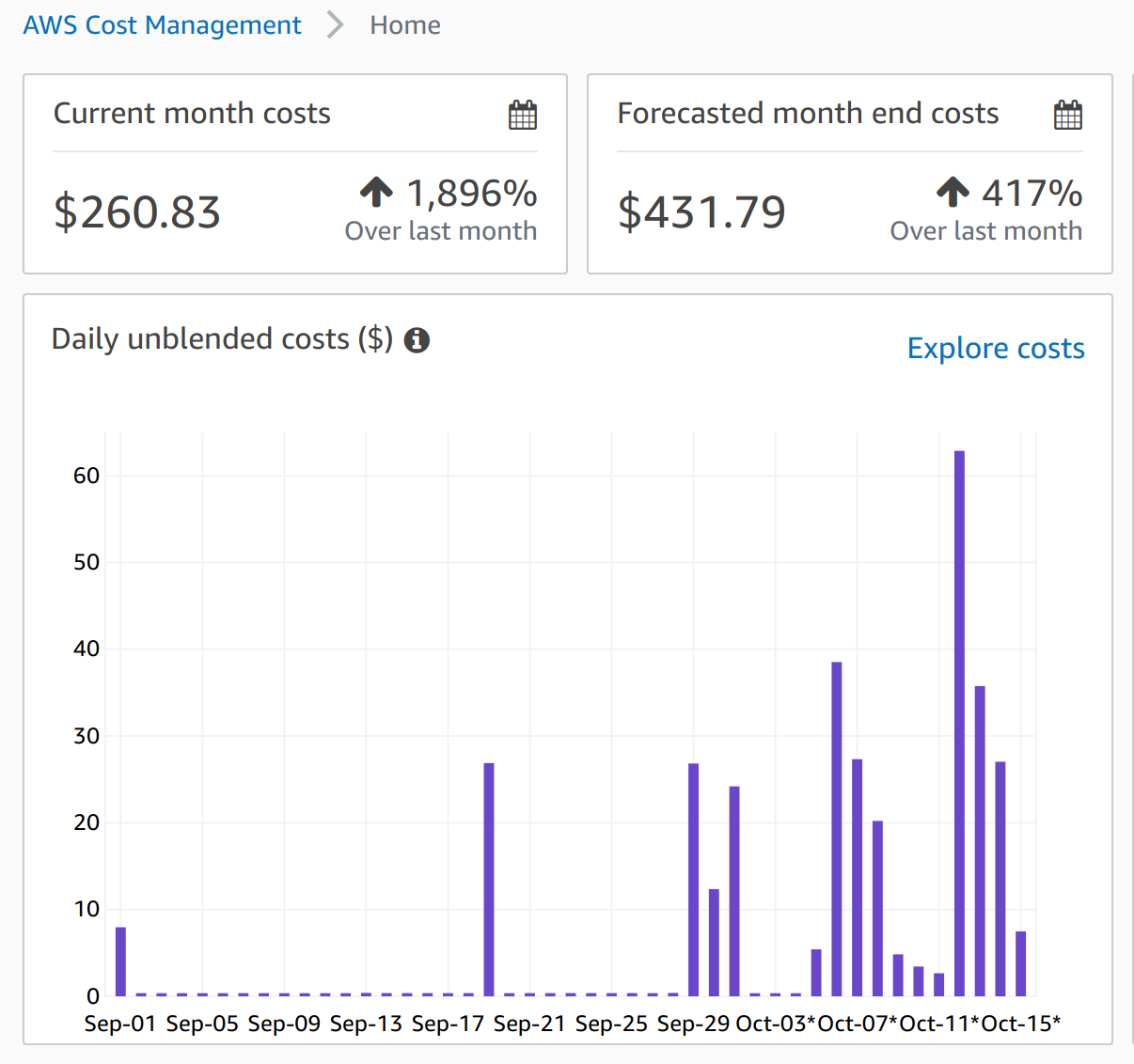
But I have been using a more expensive instance c5d.2xlarge due to a memory leak, if I do it again using more appropriate instance like r5ad.large, it should costs less than $80.